




以下是專訪實錄:
觀察者網:我們看到,中國目前在人工智能技術研發投入上可謂是不遺余力,作為人工智能行業專家,您認為持續探索人工智能技術創新之路,對整個產業和社會發展的意義是什么?
徐波:人工智能在本質上是一種賦能技術。隨著社會的持續發展和進步,人工智能作為社會經濟生活的“發動機”,無處不在的推動著多個行業的智能化發展。人工智能在不斷與行業進行融合創新的同時,會出現多種形態的變化,呈現出百花齊放的現象。
人工智能作為新一輪技術革命和產業變革的重要驅動力,已經改變很多現有的流程、理念、生產方式、組織形式,將進一步解放和發展社會生產力,深度改變人們的思想觀念。當前,人工智能正在全方位賦能商業、教育、醫療、制造、交通和社會治理,成為不可或缺的發展引擎。但人工智能發展創新絕非一帆風順,短時間內,相關技術還將經歷一個艱難爬坡、臨界點突破、再遇到新的瓶頸這樣螺旋式的發展上升過程。
觀察者網:自從國外OpenAI公司的GPT3、華為公司的盤古等人工智能模型出現以來,無監督學習迅速發展,目前預訓練大模型已經發展到了什么階段?
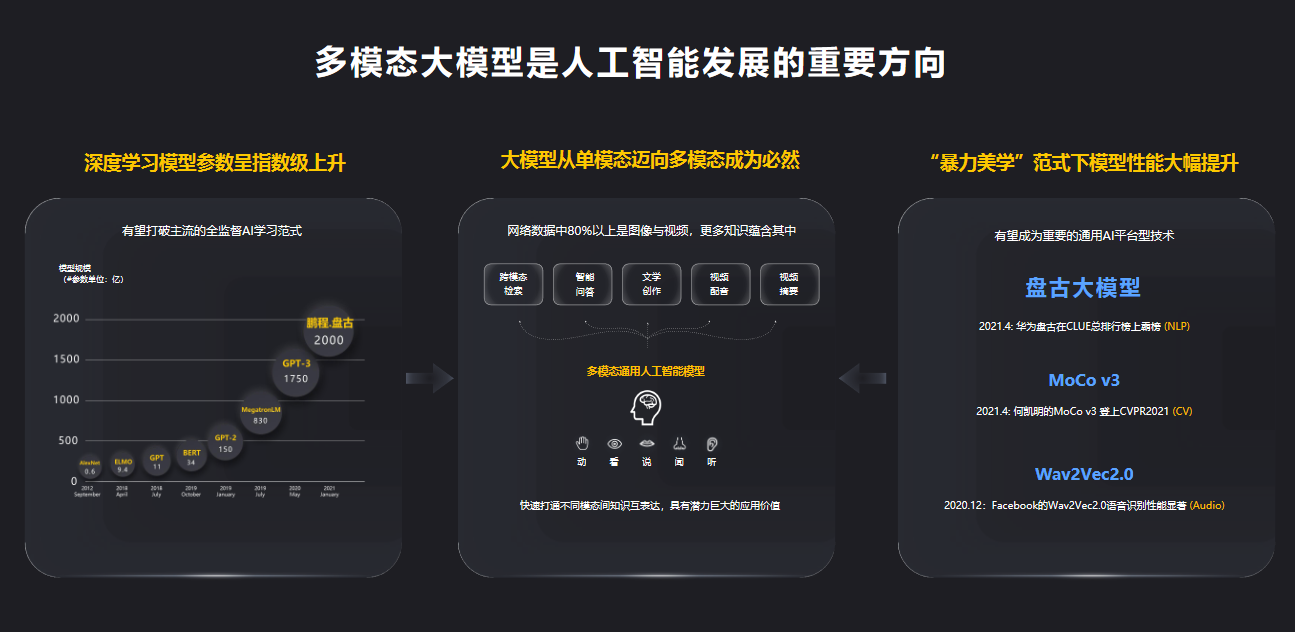
徐波:圖靈獎獲得者Yann Lecun曾經說過,如果智能是一塊蛋糕,那么蛋糕的主體是無監督學習,蛋糕上的糖衣是監督學習,蛋糕上的櫻桃是強化學習。人類對世界的理解主要來自于大量未標記的信息。
“蛋糕主體”指的是無監督學習,現在很多人工智能碰到的落地上的可信和魯棒性難題,其本質問題是現有AI缺乏語義級的認知。認知如同浮在海平面上的冰山。自然語言是冰山浮出水面的部分,而理解自然語言的基礎是大量的人類常識、背景知識、領域知識等世界知識,這是冰山水面以下看不到的部分。把這些合起來統稱為“語義空間”。現有的AI系統很難把這些語義空間加以全面準確的表達。
例如,“張三吃大碗”、“張三吃食堂”、“張三吃面條”這三句話。“張三吃大碗”并不是說張三把大碗吃掉,“張三吃食堂”也不是要把食堂吃掉,這種表述背后的邏輯可能是食堂是吃飯的地方,很多人都在食堂吃飯,張三家里可能沒做飯,所以在食堂吃飯。對人工智能來說,必須有這些相關的背景知識,才能理解“張三吃食堂”這句對人來講很容易理解的話。
人工智能需要學習很多背景知識才能理解自然語言。這就是“認知冰山”問題,冰山海平面之下才是獲得認知的關鍵。有的人工智能專家把這些大量的背景知識稱作人工智能的“暗物質”。怎么把這些“暗物質”挖掘出來放在一個系統里?無監督學習是一條路徑。
這些“暗物質”隱含存在于我們的圖片、日常對話和海量文本中。但是,目前的預訓練大多數還是單模態。“百聞不如一見”,可能很復雜的語義表述只需要看一張圖片就能理解。
同時,人類的聲音還蘊藏著情緒和感情,只有準確捕獲這些細節信息,才有可能懂得語言背后真正的含義,而不僅僅是文字表面的意思。那么,我們如何才能同時有效把聲音、圖片和文字這些信息都整合起來呢?
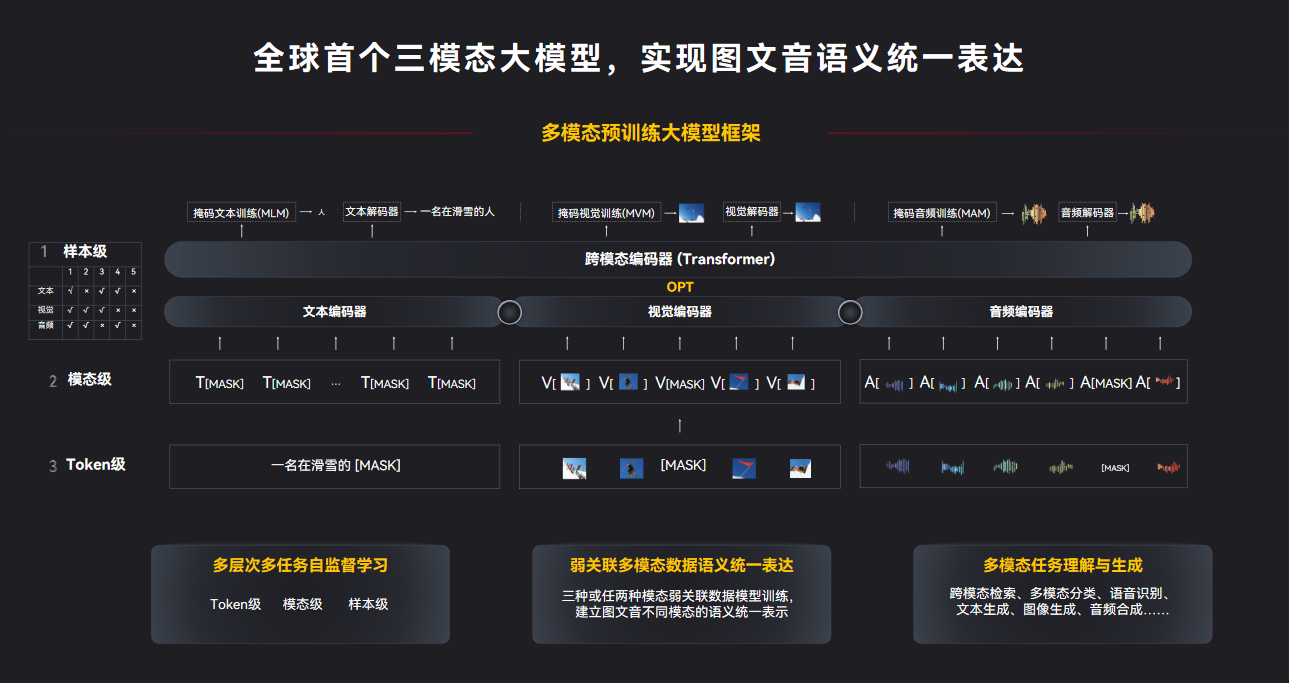
這次,我們在武漢人工智能計算中心算力支持下研發的全球首個三模態大模型“紫東太初”,在實現圖、文、音的統一表達方面取得重要進展。已有多模態預訓練模型通常僅考慮兩個模態,如圖像和文本,或者視頻和文本,不但忽視了周圍環境中普遍存在的語音信息,并且模型不好兼具理解與生成能力,難以在生成任務與理解類任務中同時取得良好表現。
我們首次將語音信息引入,并通過一個統一語義空間網絡表達生成三模態模型,可以把剛才提到的“認知冰山”或“暗物質”的龐大語義空間學習出來,能更加接近人類真正的感情和思考。特別地,由于側重交互功能的語音的加入,使我們的大模型一下子變“活”了,使人工智能邁向更高層次的通用型人工智能方向發展。
“紫東太初”三模態訓練模型采用了多層次、多任務、自監督、預訓練的學習方式,論文已經公開發表。最重要的是提出來三模態數據的語義統一表達,可同時支持三種或者任兩種模態的若干數據預訓練。這個模型不僅可以實現跨模態理解,還能實現跨模態生成,做到理解和生成兩個最重要的認知能力的平衡,首次實現以圖生音,以音來生圖的功能。
三模態大模型可能把更多人類許多與生俱來的東西學習出來,把“認知冰山”水面以下的東西能進行挖掘和表達。另外,單模態預訓練模型無疑越大越好,但三模態模型的重點更在于探索如何讓它更“巧”。三模態大模型要做好還要下很多功夫,但我們已經在正確的方向上邁出了重要的一步。
觀察者網:多模態大模型“紫東太初”名稱的內涵,是不是包涵了某種開天辟地的意義?
徐波:可以這么理解,就是相當于人工智能走向類人智能的一個混沌初開之際,也是感知智能走向通用智能重要的第一步。
一個比較有意思的話題是,人工智能領域之外的人,比如哲學、科幻領域,特別喜歡討論人工智能的一些終極問題,例如機器人可能統治人類,同時涉及一些更高層面的倫理問題。但絕大多數人工智能領域的科學家非常清楚地認知到現有人工智能距離真正的人類智能相差甚遠。
在成功研發“紫東太初”三模態模型后,我們似乎感受到比現有人工智能更為強大的通用型人工智能大門正在打開。有時候,我們甚至在思考怎么讓人工智能依附一個好的軀體,更好地感知到自然和社會環境中的信息,把類似情緒和情感的信息做進一步的處理,AI將會有更大的發展和比較好的靈活性。這種門檻一旦突破,人工智能的發展很可能會出現指數型的增長。這是一個即將呈現爆發式增長的領域。
觀察者網:這個多模態大模型的技術水平,跟國外同行相比怎么樣?
徐波: “紫東太初”是全球首個三模態大模型。目前,全世界研究單模態大模型(圖像、文本)的人比較多,研究語音大模型的相對少一些。我們是少有的同時具備圖、文、音研究儲備和基礎的研究機構。這次自動化研究所系統整理收集了積累多年的多模態數據庫,并把圖、文、音三個模態統一起來,在一個共同的語義空間去做相互的轉換和統一表述,這在全球是首次。
通過巧妙地構建一個多模態大模型,我們的圖像技術、語音技術和文本技術都超越了現有最好水平。過去業界習慣用有監督的學習,而我們的技術對有標注數據的依賴性較小,改變了人工智能訓練需要標注好的大數據的固有模式。
首先,性能業界領先的中文預訓練模型、語音預訓練模型、視覺預訓練模型是我們三模態模型的基礎。比如,視覺的預訓練模型,首次實現超越有監督學習的性能,速度比其他的方法提高8倍,在語義分割的結果上,也超越了有監督學習的水平。在中文預訓練模型里面提出來任務感知和推理增強的模型,性能相比比GPT-3明顯提升。語音預訓練模型,針對語音領域語種多樣、標注成本高的問題,實現了基于語音預訓練的多語言、多任務、低資源關鍵技術的突破,使我們用很少的有標注數據就可以實現語音識別的性能大幅度提升。
然后,我們在統一的語義空間網絡表達上實現了模態之間的高效協同和相互轉換,在多任務上取得了更卓越的性能。在跨模態檢索和圖文語義轉換方面,都比兩個模態具有更豐富的表達跟生成能力。語音加速加入后,使得我們的大模型可以跟人類做自然流暢的交互。這意味著,我們人工智能技術在共性的語義空間表征方面取得了重要進展。
觀察者網:AI應用場景的碎片化需求,正在成為AI算法落地面臨的最大挑戰。而三模態大模型能夠實現多模態對話,視頻播報,以音生圖,以圖生音,非常有意思,未來是否有可能所有問題都會通過統一的大模型來解決?
徐波:我覺得非常有可能。我們人類主要有兩種能力,一種是與生俱來的能力,到了一定的年齡,通過基本的學習就能自然地學會說話、走路。另外一種是專業技能,如果要學會彈鋼琴、水墨畫等,仍然需要長時間的專業訓練才能實現,因為這改變了人的特定知識結構。
多模態大模型為通用人工智能的研究奠定了非常好的基座。人類基本的知識、常識,看到的一些場景、物體,以及從物理世界看到的很多東西,都可以隱藏在這個大模型里面。比如要做語音識別,現在用很小的數據量可以了,甚至可以逐漸做到不需要有監督的數據學習。
預訓練模型作為基座模型雖然不是萬能的,但是人工智能的研究范式和產業范式也會出現一些變化。比如說,現在產業都在講算法開源,但算法的維護成本很高,尤其是現在人工智能的人才很稀缺,未來人工智能領域開放的可能是模型,客戶獲得大模型的接口再稍微加一點數據就能解決問題,即“大模型+小數據”,這是我們未來希望看到的大模型對產業帶來的賦能。
這個大模型技術從學術成果向產業轉化可能還需要一個過程,但我認為不會太久,未來2-4年之內這些新技術都會逐漸得到應用。
以下是專訪實錄:
觀察者網:我們看到,中國目前在人工智能技術研發投入上可謂是不遺余力,作為人工智能行業專家,您認為持續探索人工智能技術創新之路,對整個產業和社會發展的意義是什么?
徐波:人工智能在本質上是一種賦能技術。隨著社會的持續發展和進步,人工智能作為社會經濟生活的“發動機”,無處不在的推動著多個行業的智能化發展。人工智能在不斷與行業進行融合創新的同時,會出現多種形態的變化,呈現出百花齊放的現象。
人工智能作為新一輪技術革命和產業變革的重要驅動力,已經改變很多現有的流程、理念、生產方式、組織形式,將進一步解放和發展社會生產力,深度改變人們的思想觀念。當前,人工智能正在全方位賦能商業、教育、醫療、制造、交通和社會治理,成為不可或缺的發展引擎。但人工智能發展創新絕非一帆風順,短時間內,相關技術還將經歷一個艱難爬坡、臨界點突破、再遇到新的瓶頸這樣螺旋式的發展上升過程。
觀察者網:自從國外OpenAI公司的GPT3、華為公司的盤古等人工智能模型出現以來,無監督學習迅速發展,目前預訓練大模型已經發展到了什么階段?
徐波:圖靈獎獲得者Yann Lecun曾經說過,如果智能是一塊蛋糕,那么蛋糕的主體是無監督學習,蛋糕上的糖衣是監督學習,蛋糕上的櫻桃是強化學習。人類對世界的理解主要來自于大量未標記的信息。
“蛋糕主體”指的是無監督學習,現在很多人工智能碰到的落地上的可信和魯棒性難題,其本質問題是現有AI缺乏語義級的認知。認知如同浮在海平面上的冰山。自然語言是冰山浮出水面的部分,而理解自然語言的基礎是大量的人類常識、背景知識、領域知識等世界知識,這是冰山水面以下看不到的部分。把這些合起來統稱為“語義空間”。現有的AI系統很難把這些語義空間加以全面準確的表達。
例如,“張三吃大碗”、“張三吃食堂”、“張三吃面條”這三句話。“張三吃大碗”并不是說張三把大碗吃掉,“張三吃食堂”也不是要把食堂吃掉,這種表述背后的邏輯可能是食堂是吃飯的地方,很多人都在食堂吃飯,張三家里可能沒做飯,所以在食堂吃飯。對人工智能來說,必須有這些相關的背景知識,才能理解“張三吃食堂”這句對人來講很容易理解的話。
人工智能需要學習很多背景知識才能理解自然語言。這就是“認知冰山”問題,冰山海平面之下才是獲得認知的關鍵。有的人工智能專家把這些大量的背景知識稱作人工智能的“暗物質”。怎么把這些“暗物質”挖掘出來放在一個系統里?無監督學習是一條路徑。
這些“暗物質”隱含存在于我們的圖片、日常對話和海量文本中。但是,目前的預訓練大多數還是單模態。“百聞不如一見”,可能很復雜的語義表述只需要看一張圖片就能理解。
同時,人類的聲音還蘊藏著情緒和感情,只有準確捕獲這些細節信息,才有可能懂得語言背后真正的含義,而不僅僅是文字表面的意思。那么,我們如何才能同時有效把聲音、圖片和文字這些信息都整合起來呢?
這次,我們在武漢人工智能計算中心算力支持下研發的全球首個三模態大模型“紫東太初”,在實現圖、文、音的統一表達方面取得重要進展。已有多模態預訓練模型通常僅考慮兩個模態,如圖像和文本,或者視頻和文本,不但忽視了周圍環境中普遍存在的語音信息,并且模型不好兼具理解與生成能力,難以在生成任務與理解類任務中同時取得良好表現。
我們首次將語音信息引入,并通過一個統一語義空間網絡表達生成三模態模型,可以把剛才提到的“認知冰山”或“暗物質”的龐大語義空間學習出來,能更加接近人類真正的感情和思考。特別地,由于側重交互功能的語音的加入,使我們的大模型一下子變“活”了,使人工智能邁向更高層次的通用型人工智能方向發展。
“紫東太初”三模態訓練模型采用了多層次、多任務、自監督、預訓練的學習方式,論文已經公開發表。最重要的是提出來三模態數據的語義統一表達,可同時支持三種或者任兩種模態的若干數據預訓練。這個模型不僅可以實現跨模態理解,還能實現跨模態生成,做到理解和生成兩個最重要的認知能力的平衡,首次實現以圖生音,以音來生圖的功能。
三模態大模型可能把更多人類許多與生俱來的東西學習出來,把“認知冰山”水面以下的東西能進行挖掘和表達。另外,單模態預訓練模型無疑越大越好,但三模態模型的重點更在于探索如何讓它更“巧”。三模態大模型要做好還要下很多功夫,但我們已經在正確的方向上邁出了重要的一步。
觀察者網:多模態大模型“紫東太初”名稱的內涵,是不是包涵了某種開天辟地的意義?
徐波:可以這么理解,就是相當于人工智能走向類人智能的一個混沌初開之際,也是感知智能走向通用智能重要的第一步。
一個比較有意思的話題是,人工智能領域之外的人,比如哲學、科幻領域,特別喜歡討論人工智能的一些終極問題,例如機器人可能統治人類,同時涉及一些更高層面的倫理問題。但絕大多數人工智能領域的科學家非常清楚地認知到現有人工智能距離真正的人類智能相差甚遠。
在成功研發“紫東太初”三模態模型后,我們似乎感受到比現有人工智能更為強大的通用型人工智能大門正在打開。有時候,我們甚至在思考怎么讓人工智能依附一個好的軀體,更好地感知到自然和社會環境中的信息,把類似情緒和情感的信息做進一步的處理,AI將會有更大的發展和比較好的靈活性。這種門檻一旦突破,人工智能的發展很可能會出現指數型的增長。這是一個即將呈現爆發式增長的領域。
觀察者網:這個多模態大模型的技術水平,跟國外同行相比怎么樣?
徐波: “紫東太初”是全球首個三模態大模型。目前,全世界研究單模態大模型(圖像、文本)的人比較多,研究語音大模型的相對少一些。我們是少有的同時具備圖、文、音研究儲備和基礎的研究機構。這次自動化研究所系統整理收集了積累多年的多模態數據庫,并把圖、文、音三個模態統一起來,在一個共同的語義空間去做相互的轉換和統一表述,這在全球是首次。
通過巧妙地構建一個多模態大模型,我們的圖像技術、語音技術和文本技術都超越了現有最好水平。過去業界習慣用有監督的學習,而我們的技術對有標注數據的依賴性較小,改變了人工智能訓練需要標注好的大數據的固有模式。
首先,性能業界領先的中文預訓練模型、語音預訓練模型、視覺預訓練模型是我們三模態模型的基礎。比如,視覺的預訓練模型,首次實現超越有監督學習的性能,速度比其他的方法提高8倍,在語義分割的結果上,也超越了有監督學習的水平。在中文預訓練模型里面提出來任務感知和推理增強的模型,性能相比比GPT-3明顯提升。語音預訓練模型,針對語音領域語種多樣、標注成本高的問題,實現了基于語音預訓練的多語言、多任務、低資源關鍵技術的突破,使我們用很少的有標注數據就可以實現語音識別的性能大幅度提升。
然后,我們在統一的語義空間網絡表達上實現了模態之間的高效協同和相互轉換,在多任務上取得了更卓越的性能。在跨模態檢索和圖文語義轉換方面,都比兩個模態具有更豐富的表達跟生成能力。語音加速加入后,使得我們的大模型可以跟人類做自然流暢的交互。這意味著,我們人工智能技術在共性的語義空間表征方面取得了重要進展。
觀察者網:AI應用場景的碎片化需求,正在成為AI算法落地面臨的最大挑戰。而三模態大模型能夠實現多模態對話,視頻播報,以音生圖,以圖生音,非常有意思,未來是否有可能所有問題都會通過統一的大模型來解決?
徐波:我覺得非常有可能。我們人類主要有兩種能力,一種是與生俱來的能力,到了一定的年齡,通過基本的學習就能自然地學會說話、走路。另外一種是專業技能,如果要學會彈鋼琴、水墨畫等,仍然需要長時間的專業訓練才能實現,因為這改變了人的特定知識結構。
多模態大模型為通用人工智能的研究奠定了非常好的基座。人類基本的知識、常識,看到的一些場景、物體,以及從物理世界看到的很多東西,都可以隱藏在這個大模型里面。比如要做語音識別,現在用很小的數據量可以了,甚至可以逐漸做到不需要有監督的數據學習。
預訓練模型作為基座模型雖然不是萬能的,但是人工智能的研究范式和產業范式也會出現一些變化。比如說,現在產業都在講算法開源,但算法的維護成本很高,尤其是現在人工智能的人才很稀缺,未來人工智能領域開放的可能是模型,客戶獲得大模型的接口再稍微加一點數據就能解決問題,即“大模型+小數據”,這是我們未來希望看到的大模型對產業帶來的賦能。
這個大模型技術從學術成果向產業轉化可能還需要一個過程,但我認為不會太久,未來2-4年之內這些新技術都會逐漸得到應用。
以下是專訪實錄:
觀察者網:我們看到,中國目前在人工智能技術研發投入上可謂是不遺余力,作為人工智能行業專家,您認為持續探索人工智能技術創新之路,對整個產業和社會發展的意義是什么?
徐波:人工智能在本質上是一種賦能技術。隨著社會的持續發展和進步,人工智能作為社會經濟生活的“發動機”,無處不在的推動著多個行業的智能化發展。人工智能在不斷與行業進行融合創新的同時,會出現多種形態的變化,呈現出百花齊放的現象。
人工智能作為新一輪技術革命和產業變革的重要驅動力,已經改變很多現有的流程、理念、生產方式、組織形式,將進一步解放和發展社會生產力,深度改變人們的思想觀念。當前,人工智能正在全方位賦能商業、教育、醫療、制造、交通和社會治理,成為不可或缺的發展引擎。但人工智能發展創新絕非一帆風順,短時間內,相關技術還將經歷一個艱難爬坡、臨界點突破、再遇到新的瓶頸這樣螺旋式的發展上升過程。
觀察者網:自從國外OpenAI公司的GPT3、華為公司的盤古等人工智能模型出現以來,無監督學習迅速發展,目前預訓練大模型已經發展到了什么階段?
徐波:圖靈獎獲得者Yann Lecun曾經說過,如果智能是一塊蛋糕,那么蛋糕的主體是無監督學習,蛋糕上的糖衣是監督學習,蛋糕上的櫻桃是強化學習。人類對世界的理解主要來自于大量未標記的信息。
“蛋糕主體”指的是無監督學習,現在很多人工智能碰到的落地上的可信和魯棒性難題,其本質問題是現有AI缺乏語義級的認知。認知如同浮在海平面上的冰山。自然語言是冰山浮出水面的部分,而理解自然語言的基礎是大量的人類常識、背景知識、領域知識等世界知識,這是冰山水面以下看不到的部分。把這些合起來統稱為“語義空間”。現有的AI系統很難把這些語義空間加以全面準確的表達。
例如,“張三吃大碗”、“張三吃食堂”、“張三吃面條”這三句話。“張三吃大碗”并不是說張三把大碗吃掉,“張三吃食堂”也不是要把食堂吃掉,這種表述背后的邏輯可能是食堂是吃飯的地方,很多人都在食堂吃飯,張三家里可能沒做飯,所以在食堂吃飯。對人工智能來說,必須有這些相關的背景知識,才能理解“張三吃食堂”這句對人來講很容易理解的話。
人工智能需要學習很多背景知識才能理解自然語言。這就是“認知冰山”問題,冰山海平面之下才是獲得認知的關鍵。有的人工智能專家把這些大量的背景知識稱作人工智能的“暗物質”。怎么把這些“暗物質”挖掘出來放在一個系統里?無監督學習是一條路徑。
這些“暗物質”隱含存在于我們的圖片、日常對話和海量文本中。但是,目前的預訓練大多數還是單模態。“百聞不如一見”,可能很復雜的語義表述只需要看一張圖片就能理解。
同時,人類的聲音還蘊藏著情緒和感情,只有準確捕獲這些細節信息,才有可能懂得語言背后真正的含義,而不僅僅是文字表面的意思。那么,我們如何才能同時有效把聲音、圖片和文字這些信息都整合起來呢?
這次,我們在武漢人工智能計算中心算力支持下研發的全球首個三模態大模型“紫東太初”,在實現圖、文、音的統一表達方面取得重要進展。已有多模態預訓練模型通常僅考慮兩個模態,如圖像和文本,或者視頻和文本,不但忽視了周圍環境中普遍存在的語音信息,并且模型不好兼具理解與生成能力,難以在生成任務與理解類任務中同時取得良好表現。
我們首次將語音信息引入,并通過一個統一語義空間網絡表達生成三模態模型,可以把剛才提到的“認知冰山”或“暗物質”的龐大語義空間學習出來,能更加接近人類真正的感情和思考。特別地,由于側重交互功能的語音的加入,使我們的大模型一下子變“活”了,使人工智能邁向更高層次的通用型人工智能方向發展。
“紫東太初”三模態訓練模型采用了多層次、多任務、自監督、預訓練的學習方式,論文已經公開發表。最重要的是提出來三模態數據的語義統一表達,可同時支持三種或者任兩種模態的若干數據預訓練。這個模型不僅可以實現跨模態理解,還能實現跨模態生成,做到理解和生成兩個最重要的認知能力的平衡,首次實現以圖生音,以音來生圖的功能。
三模態大模型可能把更多人類許多與生俱來的東西學習出來,把“認知冰山”水面以下的東西能進行挖掘和表達。另外,單模態預訓練模型無疑越大越好,但三模態模型的重點更在于探索如何讓它更“巧”。三模態大模型要做好還要下很多功夫,但我們已經在正確的方向上邁出了重要的一步。
觀察者網:多模態大模型“紫東太初”名稱的內涵,是不是包涵了某種開天辟地的意義?
徐波:可以這么理解,就是相當于人工智能走向類人智能的一個混沌初開之際,也是感知智能走向通用智能重要的第一步。
一個比較有意思的話題是,人工智能領域之外的人,比如哲學、科幻領域,特別喜歡討論人工智能的一些終極問題,例如機器人可能統治人類,同時涉及一些更高層面的倫理問題。但絕大多數人工智能領域的科學家非常清楚地認知到現有人工智能距離真正的人類智能相差甚遠。
在成功研發“紫東太初”三模態模型后,我們似乎感受到比現有人工智能更為強大的通用型人工智能大門正在打開。有時候,我們甚至在思考怎么讓人工智能依附一個好的軀體,更好地感知到自然和社會環境中的信息,把類似情緒和情感的信息做進一步的處理,AI將會有更大的發展和比較好的靈活性。這種門檻一旦突破,人工智能的發展很可能會出現指數型的增長。這是一個即將呈現爆發式增長的領域。
觀察者網:這個多模態大模型的技術水平,跟國外同行相比怎么樣?
徐波: “紫東太初”是全球首個三模態大模型。目前,全世界研究單模態大模型(圖像、文本)的人比較多,研究語音大模型的相對少一些。我們是少有的同時具備圖、文、音研究儲備和基礎的研究機構。這次自動化研究所系統整理收集了積累多年的多模態數據庫,并把圖、文、音三個模態統一起來,在一個共同的語義空間去做相互的轉換和統一表述,這在全球是首次。
通過巧妙地構建一個多模態大模型,我們的圖像技術、語音技術和文本技術都超越了現有最好水平。過去業界習慣用有監督的學習,而我們的技術對有標注數據的依賴性較小,改變了人工智能訓練需要標注好的大數據的固有模式。
首先,性能業界領先的中文預訓練模型、語音預訓練模型、視覺預訓練模型是我們三模態模型的基礎。比如,視覺的預訓練模型,首次實現超越有監督學習的性能,速度比其他的方法提高8倍,在語義分割的結果上,也超越了有監督學習的水平。在中文預訓練模型里面提出來任務感知和推理增強的模型,性能相比比GPT-3明顯提升。語音預訓練模型,針對語音領域語種多樣、標注成本高的問題,實現了基于語音預訓練的多語言、多任務、低資源關鍵技術的突破,使我們用很少的有標注數據就可以實現語音識別的性能大幅度提升。
然后,我們在統一的語義空間網絡表達上實現了模態之間的高效協同和相互轉換,在多任務上取得了更卓越的性能。在跨模態檢索和圖文語義轉換方面,都比兩個模態具有更豐富的表達跟生成能力。語音加速加入后,使得我們的大模型可以跟人類做自然流暢的交互。這意味著,我們人工智能技術在共性的語義空間表征方面取得了重要進展。
觀察者網:AI應用場景的碎片化需求,正在成為AI算法落地面臨的最大挑戰。而三模態大模型能夠實現多模態對話,視頻播報,以音生圖,以圖生音,非常有意思,未來是否有可能所有問題都會通過統一的大模型來解決?
徐波:我覺得非常有可能。我們人類主要有兩種能力,一種是與生俱來的能力,到了一定的年齡,通過基本的學習就能自然地學會說話、走路。另外一種是專業技能,如果要學會彈鋼琴、水墨畫等,仍然需要長時間的專業訓練才能實現,因為這改變了人的特定知識結構。
多模態大模型為通用人工智能的研究奠定了非常好的基座。人類基本的知識、常識,看到的一些場景、物體,以及從物理世界看到的很多東西,都可以隱藏在這個大模型里面。比如要做語音識別,現在用很小的數據量可以了,甚至可以逐漸做到不需要有監督的數據學習。
預訓練模型作為基座模型雖然不是萬能的,但是人工智能的研究范式和產業范式也會出現一些變化。比如說,現在產業都在講算法開源,但算法的維護成本很高,尤其是現在人工智能的人才很稀缺,未來人工智能領域開放的可能是模型,客戶獲得大模型的接口再稍微加一點數據就能解決問題,即“大模型+小數據”,這是我們未來希望看到的大模型對產業帶來的賦能。
這個大模型技術從學術成果向產業轉化可能還需要一個過程,但我認為不會太久,未來2-4年之內這些新技術都會逐漸得到應用。
文章來源:觀察者網